F-IVM is a unified incremental maintenance approach for analytics over normalised databases.
Analytical tasks are expressed as views on joins with group-by aggregates over functions that map keys
to payloads.
F-IVM
has been already used for gradient computation in learning linear regression models, matrix
chain multiplication, and factorised evaluation of conjunctive queries. Although these applications
achieve
different outcomes, the insight of this project is that they only differ in the specification of the sum
and product operations over payloads. These payload operations can be: arithmetic addition and
multiplication
for queries with joins and group-by aggregates; relational union and join for listing and factorised
representation
of conjunctive query results; matrix addition and multiplication for gradient computation; in general,
sum
and product in an appropriate
ring
.
The
F-IVM
’s mechanisms for maintenance and computation over keys stay the same. Efficient incremental
view maintenance (IVM) for new analytics is readily available as long as they come with an appropriate
specification
of the sum and product ring operations.
IVM your next analytics by just providing the rings.
F-IVM
does the rest!
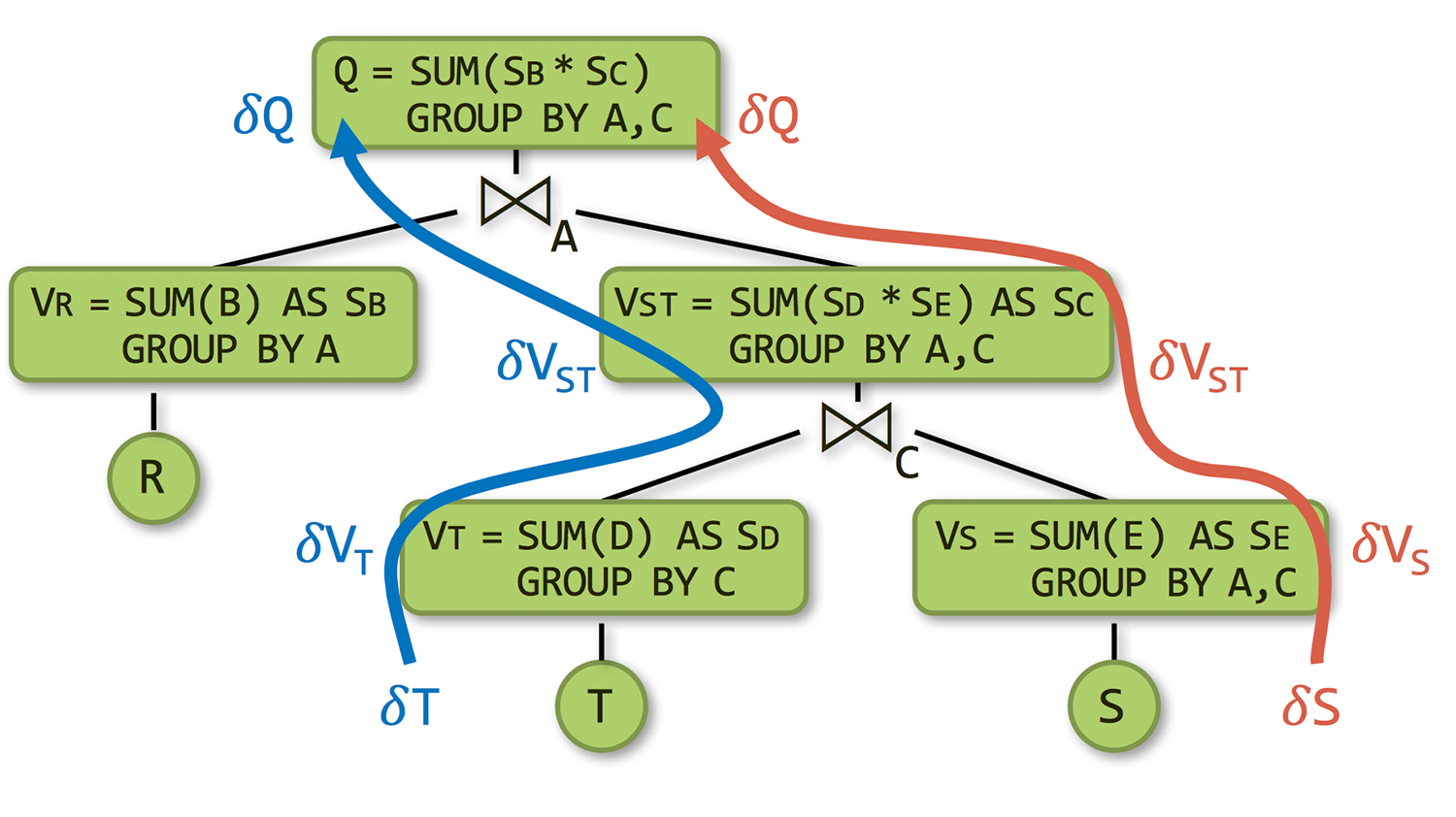
F-IVM has two ingredients:
- It leverages higher-order IVM to reduce the maintenance of the input view to the maintenance of a tree of increasingly simpler views. In contrast to classical (first- order) IVM, which does not use extra views and computes changes in the query result on the fly, by using carefully chosen extra views F-IVM can tremendously speed up the maintenance task and lower its complexity. Nevertheless, it may use substantially fewer and cheaper views than fully-recursive IVM, which is the approach taken by the state-of-the-art IVM system DBToaster.
-
It is the first approach to employ factorised computation for three aspects of incremental maintenance
for
queries with aggregates and joins:
- It exploits insights from query evaluation algorithms with best known complexity and optimisations that push aggregates past joins;
- It can process bulk updates expressed as low-rank decompositions; and
- It can maintain compressed representation of query results.
F-IVM is implemented on top of DBToaster’s open-source back- end, which can generate optimised C++ code from high-level update trigger specifications. In a range of applications, it outperforms DBToaster, classical first-order IVM, and re-evaluation by up to four orders of magnitude while using up to two orders of magnitude less space.
If you liked it, then you should put a ring on it.